大数据处理架构Hadoop 从原理到服务的全面解析
随着信息技术的高速发展,大数据已成为数字经济时代的重要生产要素。理解大数据的核心原理、处理架构和服务模式,对于把握数字化转型机遇至关重要。
一、大数据的基本原理
大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合。其核心特征通常概括为5V特性:
1. 数据体量大(Volume)
从TB级别跃升到PB乃至EB级别,数据量的爆炸式增长是大数据最显著的特征。
2. 数据类型多样(Variety)
包括结构化数据(如数据库表)、半结构化数据(如XML文件)和非结构化数据(如文本、图像、视频等)。
3. 处理速度快(Velocity)
数据产生和处理的实时性要求越来越高,需要流式处理技术支撑。
4. 价值密度低(Value)
海量数据中有价值的信息比例相对较低,需要通过复杂分析挖掘潜在价值。
5. 数据真实性(Veracity)
数据的质量和可靠性直接影响分析结果的准确性。
二、Hadoop:大数据处理的基石
Hadoop作为开源分布式计算框架,已成为大数据处理的行业标准。其核心设计思想是将大数据集分解为小块,分布到多台计算机上并行处理。
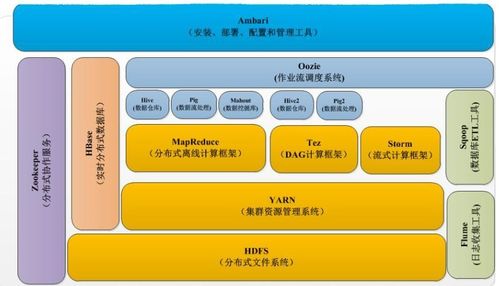
Hadoop生态系统的主要组件
1. HDFS(Hadoop分布式文件系统)
- 主从架构:NameNode(主节点)管理文件系统元数据,DataNode(从节点)存储实际数据块
- 高容错性:数据自动复制到多个节点,单点故障不影响系统可用性
- 适合大文件存储:默认块大小为128MB,优化了大文件的读写性能
2. MapReduce计算框架
- Map阶段:将输入数据分割并映射为键值对
- Shuffle阶段:对中间结果进行排序和分组
- Reduce阶段:对分组后的数据进行聚合计算
- 编程模型简单,自动处理分布式计算的复杂性
3. YARN资源管理器
- 负责集群资源管理和作业调度
- 支持多种计算框架(如MapReduce、Spark等)共享集群资源
- 提高了集群利用率和系统扩展性
4. 其他重要组件
- HBase:分布式列存储数据库,支持随机实时读写
- Hive:数据仓库工具,提供类SQL查询功能
- Pig:高级数据流语言和执行框架
- ZooKeeper:分布式协调服务
三、大数据服务的应用实践
基于Hadoop架构的大数据服务已广泛应用于各个领域:
1. 数据存储与管理服务
- 构建企业级数据湖,集中存储多源异构数据
- 实现数据的统一管理和权限控制
- 提供数据生命周期管理能力
2. 数据分析与挖掘服务
- 离线批处理分析:处理海量历史数据,挖掘深层规律
- 实时流处理:监控业务指标,快速响应市场变化
- 机器学习与AI:构建智能推荐、风险控制等高级应用
3. 数据可视化与服务化
- 通过BI工具将分析结果可视化展示
- 构建数据API服务,支持业务系统调用
- 实现数据驱动的决策支持
四、大数据技术的发展趋势
- 云原生大数据:大数据平台向云上迁移,提供弹性伸缩和按需付费服务
- 实时化处理:流处理技术重要性不断提升,满足业务实时性需求
- AI与大数据融合:机器学习、深度学习与大数据技术深度集成
- 数据安全与隐私保护:在数据利用与隐私保护间寻求平衡
- 边缘计算与物联网:分布式计算向数据源头延伸
结语
Hadoop作为大数据处理的基础架构,为企业提供了处理海量数据的能力。随着技术的不断演进,大数据服务正从单纯的技术工具向全面的数据能力平台转变。企业和组织需要深入理解大数据原理,合理运用Hadoop等工具,才能在数据驱动的时代保持竞争优势。大数据技术将继续向智能化、实时化、服务化方向发展,为各行业创造更大的价值。
如若转载,请注明出处:http://www.91927waimai.com/product/27.html
更新时间:2026-06-18 07:42:11